What can Zig learn from TypeScript, and what can TypeScript learn from Zig?
 The Advent of Code is a fun annual programming competition with an Elf theme. It consists of 25 two-part problems of increasing difficulty, released every day in December leading up to Christmas.
The Advent of Code is a fun annual programming competition with an Elf theme. It consists of 25 two-part problems of increasing difficulty, released every day in December leading up to Christmas.
Every December, I complete it in a new programming language. Every January, I intend to blog about the experience. Usually this slips to March or April, but this year it's fallen all the way back to July! As excuses, I'll offer writing a book, participating in Recurse Center and implementing a cool new feature in TypeScript 5.5.
Here are the previous installments in this series:
Solving concrete problems is fun, and so is learning new languages. But this is also a good way to break out of the mental bubble of your primary language to see what else is out there. As Alan Perlis once said, "A language that doesn't affect the way you think about programming is not worth knowing."
Like many people in the JavaScript world, I learned about Zig because Bun, the new JavaScript runtime, is implemented in it. I read a little bit about the language, thought it sounded interesting, and decided to do the 2023 Advent of Code in it.
I didn't know that much about Zig going in. My mental model was that it was a "modernized C" to complement Rust's "modernized C++." Having used Zig for a bit, I wouldn't say that any more. It can be a fine C++ replacement, too. But first things first. What's Zig?
- A very quick intro to Zig
- What can TypeScript learn from Zig?
- What can Zig learn from TypeScript?
- General impressions of Zig
- Thoughts on this year's Advent of Code
- Zig gotchas for JavaScript developers
- Tips for doing the Advent of Code in Zig
- Conclusions
A very quick intro to Zig
![]() Zig is a low-level programming language that was first announced in 2016. It fills a similar niche to C: manual memory management, access to the bits of your data structures, compatible with C APIs, no object orientation.
Zig is a low-level programming language that was first announced in 2016. It fills a similar niche to C: manual memory management, access to the bits of your data structures, compatible with C APIs, no object orientation.
C is a very old language, and some of its design choices haven't aged well. While a whole source file might not have fit into memory in 1970, that seems like a safe assumption in the 21st century. And the internet has made the cost of bugs like buffer overflows dramatically higher, since they're now security holes. Zig has a reasonable module system and it doesn't allow null pointers.
Zig also takes the opportunity to clean up and modernize lots of C syntax. One small example: in C, dereferencing a pointer is a prefix operation (*p), unless you're accessing a property (p->prop). In Zig, dereferencing is a postfix operation (p.*) and you always access properties with a dot (p.prop).
Zig also embraces best practices that have emerged over the past few decades: option types instead of null pointers, slices instead of null-terminated strings, type inference, built-in testing tools, UTF-8 source code, and a canonical code formatter.
Here's what Hello World looks like in Zig:
|
Beyond modernizing C, Zig introduces a few novel constructs of its own. We'll take a look at two of these and think about what they'd look like in the context of TypeScript.
What can TypeScript learn from Zig?
![]() Programming language designers sometimes talk about their novelty budget: if you want developers to learn your language, you can only deviate so much from languages they already know. So best to think carefully about what these novelties will be, and make sure that they're high impact.
Programming language designers sometimes talk about their novelty budget: if you want developers to learn your language, you can only deviate so much from languages they already know. So best to think carefully about what these novelties will be, and make sure that they're high impact.
Two of Zig's most novel features are Detectable Illegal Behavior and comptime. These are both fantastic ideas, and it's interesting think about what they'd look like in TypeScript.
Detectable Illegal Behavior
The earlier we can catch errors, the less damage they cause, and the better off we'll be. You can imagine a hierarchy of bad behavior:
- Worst: Incorrect runtime behavior, producing a wrong answer, or even data corruption.
- Bad: Throwing an exception or crashing at runtime.
- Better: Failing a test
- Best: Detecting the bug through static analysis (a compiler error)
(You could add more levels to this hierarchy, e.g. unit tests, integration tests and manual QA tests.) Detection through static analysis is best because we detect the bug without ever having to run the broken code, and it can't do any damage!
Languages like C are notorious for the high consequences of mistakes. Coding errors can often turn into memory corruption or security issues. Zig's "detectable illegal behavior" is an interesting take on how to improve this. To see how it works, consider an integer overflow bug:
|
A u8 is an 8-bit unsigned integer. It can only represent values from 0 to 255. When you compile this, you'll get an error:
|
This is the best case scenario. A u8 can't represent 256 and Zig has detected this error statically.
If you make the error a little more subtle, though, the Zig compiler can't see it:
|
What happens now is that you get a crash when you run the program:
|
Zig knows that integer addition can cause an overflow, so it inserts a check for this at runtime. If you overflow, you get a panic. Looking at our hierarchy of bad behavior, this is bad but it's saving us from the worst case scenario: incorrect behavior and chaos at runtime. This comes at a cost, though: because the check happens at runtime, it slows your program down. If this addition is happening in a tight loop, this can be a problem.
Zig lets you take off the safety wheels by changing your release mode:
|
Now the safety checks are off and the integer overflow is allowed to happen. There are many more examples of this sort of detectable illegal behavior in Zig, for example bounds checking on arrays. (Zig doesn't guarantee that this code will output 0. This is also known as "undefined behavior," and this flexibility gives Zig more opportunities for optimization.)
The interesting thing here is that there's an intermediate between detecting problems statically and not detecting them at all. As a fallback, we can detect a class of problems at runtime in debug builds.
What would this look like in TypeScript? JavaScript's approach to numbers means that integer overflows are uncommon. But array out-of-bounds access can certainly happen:
|
TypeScript does not modify this code when it compiles to JavaScript. But you could imagine tsc compiling this to a sort of "debug build" that added bounds-checking:
|
There's no static error, but at least this moves us one notch up the hierarchy of bad behavior.
It's instructive to compare Zig's behavior to TypeScript's noUncheckedIndexedAccess setting. Zig's approach is "trust but verify:" during static analysis, it assumes your code is correct and only reports an error if it's confident that it's not. But then it inserts checks to verify its assumption at runtime.
By contrast, TypeScript with noUncheckedIndexedAccess assumes your code is invalid unless it can prove otherwise. There's a presumption of incorrectness, but no runtime checks are added:
|
One of the ways to convince TypeScript that your array access is valid is to add a bounds check yourself:
|
Inserting runtime checks would allow TypeScript to flip over to an "innocent unless proven guilty" model like Zig's, which would result in fewer false positives and make noUncheckedIndexedAccess easier to adopt.
This is just one instance of the broader issue of unsoundness. This is when a variable's TypeScript type doesn't match its runtime type. There are many ways this can happen, but a common one is a type assertion ("as"):
|
Does this API endpoint actually return a FunFact? The type assertion assures TypeScript that it does, but there's no reason this has to be the case at runtime. When this snippet is converted to JavaScript, it looks like this:
|
There are no checks performed on the response. TypeScript is just trusting us. But perhaps the API has changed or we had a miscommunication with the backend team. If the response is actually some other type, then we may get a runtime crash or display unsightly "undefined"s on the page.
There are various standard ways to solve this problem in TypeScript. But what if TypeScript were a little more like Zig? What if it had some notion of a debug build that produced JavaScript that looked more like this:
|
This could be pervasive. For example, a function like this:
|
might get compiled to this:
|
You can imagine how this would improve type safety, but also slow down your code at runtime.
The Dart language does something like this to achieve a sound type system. It's interesting to think about what something similar would look like for TypeScript. I'm sure it would find lots of surprising sources of unsound types!
comptime
In Zig, you can use the comptime keyword to force a block of code to execute at compile time, rather than runtime:
|
If you build this and then run it, you'll see the first line print instantly, then a noticeable pause before the second line prints the same number. When Zig compiles this code, it becomes something more like this:
|
In the first line, the compiler has run the Fibonacci function.
comptime is a particularly powerful, unifying concept in Zig because you can also manipulate types at comptime. This is how Zig implements generic types:
|
Notice how this is just an ordinary Zig function, written with all the usual syntax and constructs. It's a function from from one type to another. This is how we think about types in TypeScript (Item 50 of Effective TypeScript is called "Think of Generics as Functions Between Types"). But in Zig they really are functions between types. Notice on the last line how "instantiating" a generic type just involves calling the function and assigning the result to a variable.
Compare this to what you'd write in TypeScript:
|
TypeScript has two Turing-complete languages: JavaScript for the runtime, and TypeScript's type system for type manipulation. The two are quite different, and TypeScript developers have to learn a new language to write complex, type-level code. Moreover, as I argue in Item 58 of Effective TypeScript, it's not a particularly good language, and you should try to avoid doing too much heavy lifting in it lest you fall into the infamous Turing Tarpit.
Zig, by contrast, only has one language: Zig. To manipulate types, you just write Zig code. The only difference is that it has to be comptime. Manipulating the properties of a type doesn't require any new concepts like mapped types or conditional types. You just use a for loop and an if statement.
In my 2020 post TypeScript Splits the Atom and Item 54 of Effective TypeScript, I walk through how you can construct a generic type that takes a snake_cased object ({foo_bar: string}) and produces the corresponding camelCased object ({fooBar: string}). This requires a bunch of concepts from TypeScript's type system: generic types, template literal types, conditional types, mapped types, and infer. It's not simple, and it doesn't look at all like JavaScript.
Here's what it might look like if TypeScript had something like Zig's comptime:
|
This is just a sketch, but it's satisfying to see how the code for manipulating the types and the code for manipulating the values are nearly identical. Even better, they both call the same camelCase function, so you know the type and value transformations will stay in sync and have identical edge case behaviors.
Type-level TypeScript is written in a different language and runs in the type checker. comptime Zig is still Zig, it just runs at a different time.
comptime is useful beyond type manipulation. I was afraid to look at the source code for std.fmt.format because I assumed it would involve some completely inscrutable metaprogramming. But it's actually pretty simple! The format string must be comptime known, and the formatting function just runs a for loop over it.
Using the same language for programming and metaprogramming seems like a great idea (see: Lisp macros). Are there any downsides? I can think of two: performance and inference.
Performance:
comptimeisn't free. Your code still has to be run at some point. Zig doesn't have a very built-out language server (more on that shortly), but TypeScript does. It potentially has to run your type level code on every keystroke as you type in your text editor. To avoid bogging down or hanging, TypeScript sets some strict limits on how deeply recursive your type-level code can be. If your type-level code was written in JavaScript, it would much harder to enforce these limits in any systematic way. Timeouts aren't really an option in a compiler: you don't want the validity of code to depend on the developer's CPU speed.Inference: When it's inferring types, there are situations where TypeScript needs to run your type-level code in reverse. Type-level operations were built with inference in mind, but inverting an arbitrary snippet of JavaScript code isn't possible.
Here's a simple example of how this can happen:
|
Here Box maps T → {value: T}, but on the last line TypeScript has to go from {value: number} → number to infer T. This even works with conditional types.
These are both serious issues. In practice I'd hope that caching could mitigate many of the performance concerns. And, to be honest, I'd be fine losing this form of type inference if it meant that we could manipulate types in plain old JavaScript!
To be clear, these would be radical changes to TypeScript and I don't expect anything like them to happen. But you could imagine building an alternative TypeScript to JavaScript emitter that inserted runtime type checks. (We could call it… DefinitelyTyped! 😜) And if an aspiring language designer wants to build the next great flavor of typed JavaScript, including a comptime construct would be a great way to differentiate from TypeScript.
What can Zig learn from TypeScript?
 Flipping the question around, what are some good ideas from TypeScript that Zig might adopt?
Flipping the question around, what are some good ideas from TypeScript that Zig might adopt?
My main suggestion would be to focus more on developer experience. To me, this means a few things:
- Language server
- Error message ergonomics
- Documentation
Language Server
When you install TypeScript in a project, you get two binaries:
tsc, the TypeScript Compilertsserver, the TypeScript Language Server
It's pretty rare to run tsserver directly, but if you use VS Code or another editor that supports the language service protocol, you're interacting with it all the time. The TypeScript team treats these binaries as equally important. Every new language feature is supported by the language server on day one. And the release notes for TypeScript versions include things like new Quick Fixes, which you might not think of as being core to the language itself.
There is a language server available for Zig, zls. It's a third-party tool, though, and while an enormous amount of work has gone into it, it has a lot of issues. It provides syntax highlighting and some language service features like go-to-definition. It reports superficial errors like syntax errors and unused variables, but it quickly gets lost with anything much beyond that.
Some of the errors that it fails to report are surprising:
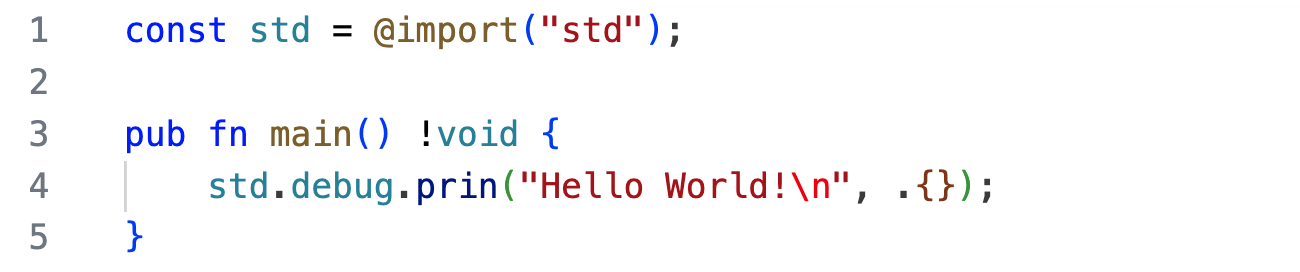
It should be print, not prin.
It's pretty disorienting to see no errors in your editor, only to have lots of them when you build from the command line. (See below for how to improve this.) The language server also hangs a lot. It was quite rare for me to solve an Advent of Code problem without having to restart zls.
Apparently gripes about zls are common in the Zig community, so this may not come as much of a surprise. Andrew Kelley talks about this a bit in the context of the 2024 Zig Roadmap. He thinks a first-party language server will happen eventually, but it's not a priority. He also mentions that he uses vim and does not use a language server, so a first-party language server would not benefit him personally.
I think this may be a cultural thing. I used to use vim 15 years go when I worked primarily in C++, and I also didn't use a language server. There wasn't much point. C++ is nearly impossible to parse, let alone analyze. It was only when I started working in TypeScript and switched to VS Code that I saw the light. Language servers are great, and it's hard to go back once you're used to them.
A language server changes your relationship with the language. A command-line compiler is all about looking over your code and telling you where you've made mistakes. A language server is like a partner that's right there in your editor with you, helping you to get things right. It's hard to underestimate how valuable a good language server is when you're coming up to speed on a new language. It lets you quickly experiment and develop an intuition for how types work and what errors result from your changes. A better zls would have greatly improved my experience with Zig.
Let's all hope Andrew works on a TypeScript side project someday and has a language server conversion experience. May I suggest the 2024 Advent of Code? 😀
Error Message Ergonomics
The user interface of a compiler consists mostly of the errors that it presents to you. So the way those error messages are presented has a huge impact on your experience of using the language. The TypeScript team takes this extremely seriously. There's an entire GitHub Issue Label for error messages, and many releases include improvements in error reporting.
Even more fundamental than messaging, though, is attribution. I ran into at least three cases during the Advent of Code where an error was correctly reported, but in the wrong place. This makes for an incredibly confusing experience, particularly when you're learning a new language and aren't very confident about how you're using it.
When I updated to Zig 0.13 for this post, I was happy to see that 2/3 of these misattributions had been fixed. The third issue was that calling std.debug.print with the wrong number of arguments doesn't include the relevant line number in the error message. I filed an issue about this in January. A fix was quickly posted, but it was rejected by Andrew Kelley, Zig's creator, as too hacky.
I have tremendous respect for Andrew's willingness to hold out for a better solution. Language designers need to do this to avoid bigger problems down the road. But I do hope this issue gets fixed, because missing locations on error messages is a truly terrible, disorienting user experience.
Here was another sort of error that tripped me up a few times:
|
The mistake here isn't on that line, and it doesn't have to do with the number of arguments. Rather, it's that I forgot to call .init() on the hash map:
|
I also found Zig pointer types to be pretty hard to read in error messages.
Documentation
Microsoft publishes an official TypeScript Handbook. When it launched in 2021, it was given as much attention and fanfare as the release of a new version of TypeScript itself.
I primarily used ziglearn.org to come up to speed, which is now zig.guide. There's a lot of content there, but I found it had quite a few gaps. For example, the documentation on build.zig is quite sparse, and it didn't give me much insight into how to set up a 25-day Advent of Code project (One binary? 25?). (Update: there's now an official docs page and a community forum post.)
I was surprised that Zig didn't have a toString() convention. Twenty days into the 2023 Advent of Code, I learned that it did (pub fn format) from reading the standard library source code. As it turns out, this does appear in one example in the docs on formatting, but I'd expect this to be given more front-and-center treatment since it's so useful any time you define a data structure.
Caveats
After sharing a draft of this post, I learned that's it's possible to get zls to display all compile-time errors using the buildOnSave feature. Here's a commit where I added it to my repo. I wish I'd known about this last December, it would have greatly improved my Zig experience!
And despite my grumblings about some aspects of developer experience, Zig may be making the correct tradeoffs. Why? It's still an early-stage language whose design is in flux. This is reflected not just in the version number (pre-1.0!) but also in its development: a recent release removed an existing async/await feature while they think about a better design. It's hard to imagine TypeScript doing something like that. If you expect the language to make major changes before 1.0, then building out a language server now will create more work down the road.
On the other hand, if the Zig team built out a language server now, they might gain valuable insights about which language features work well with it and which ones don't. This could inform the future design of the language. There's an assumption that a high-quality language service can be built after the language design is stabilized, but this might not be the case. It's a gamble!
Of course, another big difference between TypeScript and Zig is that Microsoft's annual revenue is nearly 500,000 times greater than the Zig Foundation's. This means that the Zig team needs to make harder choices about prioritization. Their top four goals are currently performance, language improvements, standard library improvements, and a formal language specification. It's hard to argue with the focus on build speed (Advent of Code solutions aren't big enough for this to be an issue), and that will definitely be a boon for developer experience. But I'd love to see other forms of DX move up that list. For what it's worth, TypeScript's experience with formal specification is that it's not worthwhile. A formal spec was released in 2014 and has been gathering dust ever since.
✨ Many thanks to the Zig Forum for feedback on this section.
General impressions of Zig
Those issues aside, I wound up really liking Zig! Given a choice, I'd strongly prefer it to C for a new project. I also found it easier to work in than Rust.
Zig advertises "No hidden control flow" and "No hidden memory allocations." I incorrectly read the latter to also mean "no hidden copying," and this led to a lot of confusion at first. For example:
|
In JavaScript, Python, or Java, var b = a would create a new reference to the same underlying object and this would print two 2s.
In Zig (as in C++ and Go), var b = a creates a copy of the struct and you get two different values:
|
Zig implicitly copies data all the time. Sometimes this can be subtle. If you return a struct from a function, it may be copied. A slice is a struct with a len and a ptr, and these are copied when you assign to a slice (the pointer is copied, not the thing it points to). Understanding implicit copying and building a mental model for it was the key insight that made me feel comfortable programming in Zig. I had a similar insight about Go back in 2021.
As I mentioned above, I really liked comptime. It's a clever, unifying idea. I hope more languages adopt something like this in the future.
Just like C, Zig doesn't have classes or inheritance, but it does have structs. Unlike in C, a Zig struct can have methods defined on it and it can be generic. This feels a lot like C with Classes. Unless you're making heavy use of inheritance (and why would you be?), this means that Zig can also fill many of the same niches as C++. It's interesting that structs can have private functions but not private fields. I guess this makes some sense since you have to be able to copy the bytes of a struct to use it.
Most Advent of Code problems start with reading a text file (your puzzle input). The standard way to read a file line-by-line is a bit verbose:
|
I thought it would be an interesting exercise to factor this out into a helper function. This wound up being dramatically harder than I expected. With some help from Stack Overflow and the Zig Forum, I was eventually able to come up with a solution. But the broader point from the forum was that maybe factoring this out isn't worth the hassle in Zig, because it's easier to see how all the pieces fit together with the explicit code, and to see what constants you're assuming (1024 and \n).
I eventually found another reason to avoid this pattern: if you read the entire input into a single buffer (rather than line by line), then you can assume this memory is available throughout execution and reference slices of it without having to think about ownership. This is particularly nice if you're putting them in a StringHashMap, which does not take responsibility for ownership of its keys.
Zig has a distinctive way of handling errors: it introduces special syntax (error!type) for something that can be either an error or a success value. Typically the error type can be inferred:
|
The try keyword checks if the other call returns an error and passes it on up the call chain. The possible error types that foo() returns will be the same as the other function. If foo() had returned u32 instead, then it would have needed to handle the error case itself.
I didn't wind up having very strong feelings about this feature. I almost always allowed error types to be inferred, so the only difference between this and JavaScript-style exceptions is that there were more trys. Remember, no hidden control flow. It wasn't obvious to me why some failure modes (out of memory) are handled with explicit errors, while others (integer overflow) are handled via detectable illegal behavior. (See this comment for an explanation.)
Whether a function can fail affects the way you call it, and this can be seen as an interesting nudge. Error-returning functions must be called with try, catch, or some other error-handling construct. Because you're constantly writing try, you're always aware of which type of function you're working with. This makes you prefer calling functions that can't fail. Since memory allocation can fail, this pushes you to write functions that don't allocate memory. Usually this means taking a buffer as an argument, or allocating one internally. And this is generally a more efficient design.
Another interesting choice is to not allow function closures. Instead, higher-level Zig functions like std.mem.sort take a context object that's passed to the comparison function. I believe this is equivalent in power to closures, it just requires the tedium of defining a context data type and populating it. This makes you aware of the context that you're capturing, and encourages you to capture as little as possible.
It's worth remembering that the Advent of Code tends to highlight specific aspects of a language, and these puzzles may not be the sorts of problems that the language is designed to solve. There were large parts of Zig that I never interacted with, for example its SIMD support or its C API. Zig is a great language for targeting WASM, but I never needed to do this.
A few other quick notes:
- An Arena allocator has some similarities to Rust-style lifetime annotations. Rather than tying the lifetimes of two values together, you connect them both to a moment in time during execution.
- Zig recently added destructuring assignment for tuples. This is great, but I wish it supported a similar syntax for structs, just like JavaScript, to encourage consistent naming. This would be particularly handy for imports. It's unlikely to happen, though.
- Payload capturing is ubiquitous and felt pretty intuitive. I just wish it worked better with the language server.
- Sentinel termination feels like a trivial generalization of null termination. Are there ever situations where you want to terminate a slice with anything other than a
0? (See discussion.) - Zig does a pretty good job of inferring types where it can. The various integer types make this a harder problem than it is in TypeScript, though.
- I found the many, sight variations on pointer syntax quite hard to read and get comfortable with, particularly in error messages:
*T: pointer to a single item[*]T: pointer to many (unknown number) of items*[N]T: pointer to an array of N items[*:x]T: pointer to a number of items determined by a sentinel[]T: slice, has a pointer of type[*]Tand alen.
Thoughts on this year's Advent of Code
I completed the 2017 Advent of Code in Zig as a warmup, then did the 2023 Advent of Code as problems came out each day.
This made for quite a contrast. The 2017 Advent of Code was very, very easy (my notes are here). The 2023 Advent of Code was quite hard. Even day 1 had potential for trouble. Some of the problem setups were quite convoluted. There's been speculation that this was an attempt to thwart AI solvers. Whether or not it succeeded, it certainly led to some tedious code.
I learned about a few new things this year:
- Pick's Theorem relates the area of a polygon with integer vertices to the number of integer points inside the polygon.
- The Shoelace Formula is the standard way to find the area of a simple polygon.
- A Nonogram, aka Paint by Numbers, is a type of logic puzzle.
- sympy is a Python library for symbolic manipulation / computer algebra.
Notes on a few specific problems (spoiler alert!):
- Day 20: This one was super frustrating. I had the right idea for part 2, but I used an online LCM calculator and mistyped a number, leading to the wrong result. I wasted over an hour before realizing the mistake. Note to self: always copy/paste numbers, never type them!
- Day 21: I solved this by plugging numbers into a spreadsheet and looking for a pattern, even without fully understanding it. Judging by my finish number (#4624 at 11 AM Eastern), this was the hardest problem of the year.
- Day 24: I completed part 1 before going to a family Christmas. I had part 2 in the back of my head all day, and I was pretty sure I had the solution all figured out. I just needed to code it. When I got home, I realized that the sample input and my puzzle input were very different, and my idea wouldn't work at all. I wound up spending an enormous amount of time solving the equations, largely by hand. I was a bit disappointed that most people just plugged them into sympy to get a solution without any understanding. sympy does look cool, though!
- Day 25: My turn to use a Python library without understanding what I'm doing. I gave up on Zig and plugged in NetworkX. The
k_edge_componentsmethod solves this problem. I did eventually wind up porting my solution to Zig.
Zig gotchas for JavaScript developers
Zig is a much lower-level language than JavaScript. If you haven't previously worked in a language with manual memory management, pointers, or a non-primitive string type, it's going to have a steep learning curve.
That being said, Zig has a few keywords that also exist in JavaScript, but mean completely different things. Watch out for these false friends:
varandconst: These are not analogous tovar/letandconstin JavaScript. In JavaScript,constis shallow. It just means that you can't reassign the variable. Some people don't like it. Zig'sconstis much stronger. If you declare a variable withconst, you can't mutate it or call any methods that might mutate it. It's a deepconst. Seeingvarin JS should make you flinch because of its weird hoisting semantics. But Zig doesn't have that historical baggage.varis a great term for something that varies.tryandcatch: In JavaScript (and C++, Java, and many other languages), these are used to constructtry {} catch (e) {}blocks. In Zig, they're more like operators on expressions.try f()callsf, checks if it returns an error, and returns that error if it does.catchis used to provide fallback values:f() catch valresolves tovaliffreturns an error.nullandundefined: JavaScript finally has company: another language that has bothnullandundefined! These have pretty specific meanings in Zig, though.nullis used exclusively with optional types.undefinedis special: it's not a value; instead it means that you don't want to initialize the value. Generally you want to avoid this since you'll get garbage at runtime.forandwhile: Zig'sforloop is quite limited. You can iterate over a slice or a range with it, and that's about it. For everything else, including iterators and C-stylefor(;;)loops, you use awhileloop.||andor: In JavaScript (and C),||is logical or. Like Python, Zig spells thatorinstead. Fair enough. What's really confusing, though, is that Zig also has a||operator that does something totally different. It unions two error sets, more akin to TypeScript's type-level|. I never used||.- Zig has a
switchstatement but it works a bit differently than JavaScript's. It's more powerful, doesn't have fall-through, and must be exhaustive. - Zig uses a different syntax for object literals:
.{ .x=1, .y=2 }instead of{ x: 1, y: 2 }. I screwed this up countless times, and so will you. - Zig also has tagged unions but they're a little more constrained than TypeScript's.
Zig is still a relatively niche language and ChatGPT is going to have more trouble helping you write it than it would with JavaScript.
Tips for doing the Advent of Code in Zig
Various other blogs have mentioned struggling to do AoC in Zig. For the most part, I didn't find it to be too bad. If you decide to try it, good luck! Feel free to use my repo as a template and guide.
Here are a few specific tips:
- Zig doesn't have a scanf equivalent and regexes are inconvenient. So for parsing inputs, it's split, split, split. I wound up factoring out a few
splitIntoBufandextractIntsIntoBufhelpers that made short work of reading the input for most of the problems. - Zig supports all sizes of ints, all the way up to
u65536. If you're getting overflows, try using a bigger integer type. I usedu128andi128on a few problems. std.meta.stringToEnumis a neat trick for parsing a restricted set of strings or characters.- As mentioned above, you can define a
formatmethod on yourstructs to make them print however you like. - Try to avoid copying strings to use as keys in a
StringHashMap. This feels natural coming from JS, but it's awkward in Zig because you need to keep track of those strings to free them later. If you can put your keys into astructor a tuple, that will work better because they have value semantics. If you need strings, you might be able to use slices of your puzzle input, as described above. - Watch out for off-by-one bugs with numeric ranges. If you want to include
max, it'smin..(max+1), notmin..max. - Your code is going to have a lot of
@intCast. It's OK. - I found it odd that Zig has a built-in
PriorityQueuebut no built-inQueue. I wound up finding one online that I could paste into my repo. (Update: usestd.SinglyLinkedList) - A lot of the functions you use to work with strings are in
std.mem, e.g.std.mem.eqlandstd.mem.startsWith. - Use
std.meta.eqlto compare structs, not==. - There's a trick for slicing by offset and length:
array[start..][0..length]. - It's often useful to memoize a function in Advent of Code. I have no idea if there's a general way to do this in Zig. (This led me to a unique solution that I was proud of on day 12.)
- Debug build are considerably slower than optimized builds, sometimes 10x. If you're within a factor of 10 of getting an answer in a reasonable amount of time, try a different release mode.
- Don't mutate an
ArrayListas you iterate through it. You might change what.itemsrefers to, which will lead to chaos. - You may need to factor out a variable to clarify lifetimes in some situations where JavaScript would let you inline an expression. See this issue.
Here are a few other blog posts I found helpful in learning Zig for Advent of Code:
Conclusions
I thoroughly enjoyed doing the Advent of Code and I enjoyed learning Zig in the process. Zig and TypeScript occupy different niches and have different goals, but there are still a few things they can learn from each other.
There's less than five months until the 2024 Advent of Code starts! Which language will I use this year? After learning a bunch about programming languages at Recurse Center this winter, I'm thinking that I should just bite the bullet and use Haskell. We'll see how I feel about that in December!
