In most programming languages a variable has a type and that type does not change. But one of the most interesting aspects of TypeScript's type system is that a symbol has a type at a location. Various control flow constructs can change this type:
|
 Dall-E's interpretation of TypeScript's control flow graph and type inference algorithm.
Dall-E's interpretation of TypeScript's control flow graph and type inference algorithm.This is known as "refinement" or "narrowing." When I look at TypeScript code, I read it from top to bottom and I think about how the type of x changes as execution moves through each conditional. This works well but, as I learned from my recent work adding a new form of type inference in the TypeScript compiler, it's not at all how type inference is actually implemented!
For users of TypeScript, reading code from top to bottom works just fine. But if you're working in the TypeScript compiler itself, you'll need to know how type inference works "under the hood." The key to this is "Flow Nodes," which are the nodes in the Control Flow Graph. I had a remarkably hard time finding documentation about FlowNodes online. The official Compiler-Notes repo just has a "TODO" to document them. Basarat's TypeScript guide makes no mention of them in the section on the TypeScript Compiler.
I learned a lot about FlowNodes from implementing #57465 and this post is my attempt to write the "missing manual" on them that I wish I'd had a few months back.
Confusion
My first clue that type inference didn't work the way I expected came from reading a PR that Anders Hejlsberg wrote in 2021 to add "aliased conditions" to type inference. This let you write something like:
|
In my top-to-bottom way of thinking about type inference, it seemed like there must be some kind of "tag" associated with the isNum variable indicating that it refined the parameter x. But looking at Anders' PR, this wasn't at all how it worked. He wasn't storing any information whatsoever! Instead, all I saw was a bunch of references to flow nodes. So clearly these were important.
When TypeScript parses your code, it forms an Abstract Syntax Tree (AST). Any node in the TypeScript AST can have an associated "flow node." The best way to view the TypeScript AST is David Sherret's TS AST Viewer. When you click on a node, it shows you its FlowNode. This consisted of some flags, a node, and one or more "antecedents." Curiously node.flowNode.node was never the same as node. It was always some other node in the AST.
 A Flow Node and its antecedent in the TS AST Viewer. I didn't find this view very illuminating.
A Flow Node and its antecedent in the TS AST Viewer. I didn't find this view very illuminating.
Graph Visualization and an Insight
The antecedents were other FlowNodes. These seemed to form some sort of graph structure, so I thought that visualizing them might help. I'd used GraphViz and the dot language to create graph visualizations on a previous project, and this seemed like a natural addition to the TS AST Viewer. I learned later that there was already a TypeScript playground plugin that did something similar.
Seeing this graph made it much clearer what was going on. This was the control flow graph in reverse! An if statement came out as a diamond shape:
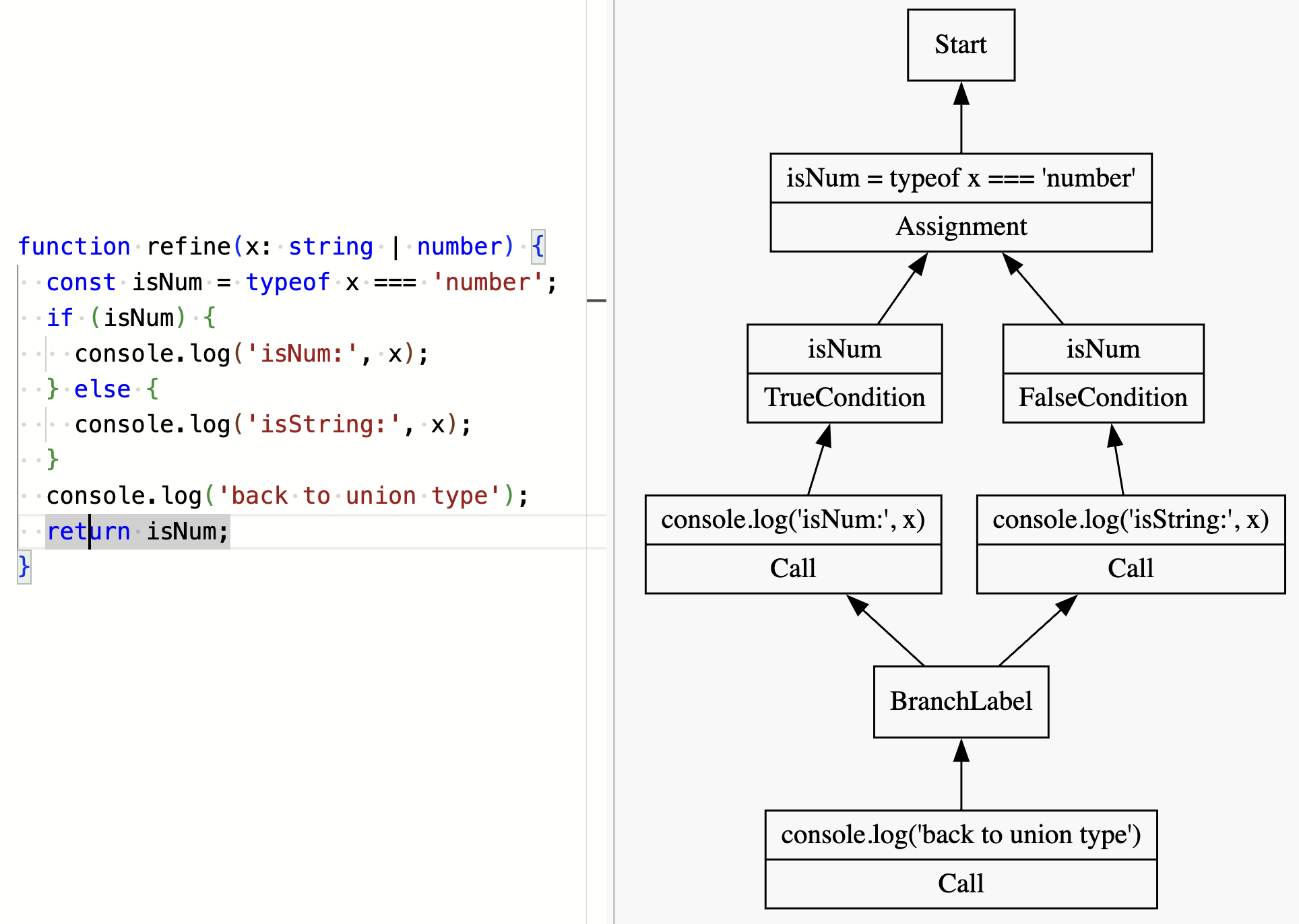 Full control flow graph showing a diamond shape for branching code.
Full control flow graph showing a diamond shape for branching code.
I showed this to a batchmate at Recurse Center who had the key insight: a Node's Flow Node is the previous statement that executed. With branching constructs, there will be more than one possible previous statement.
With loops, the graph can even have a cyclic:
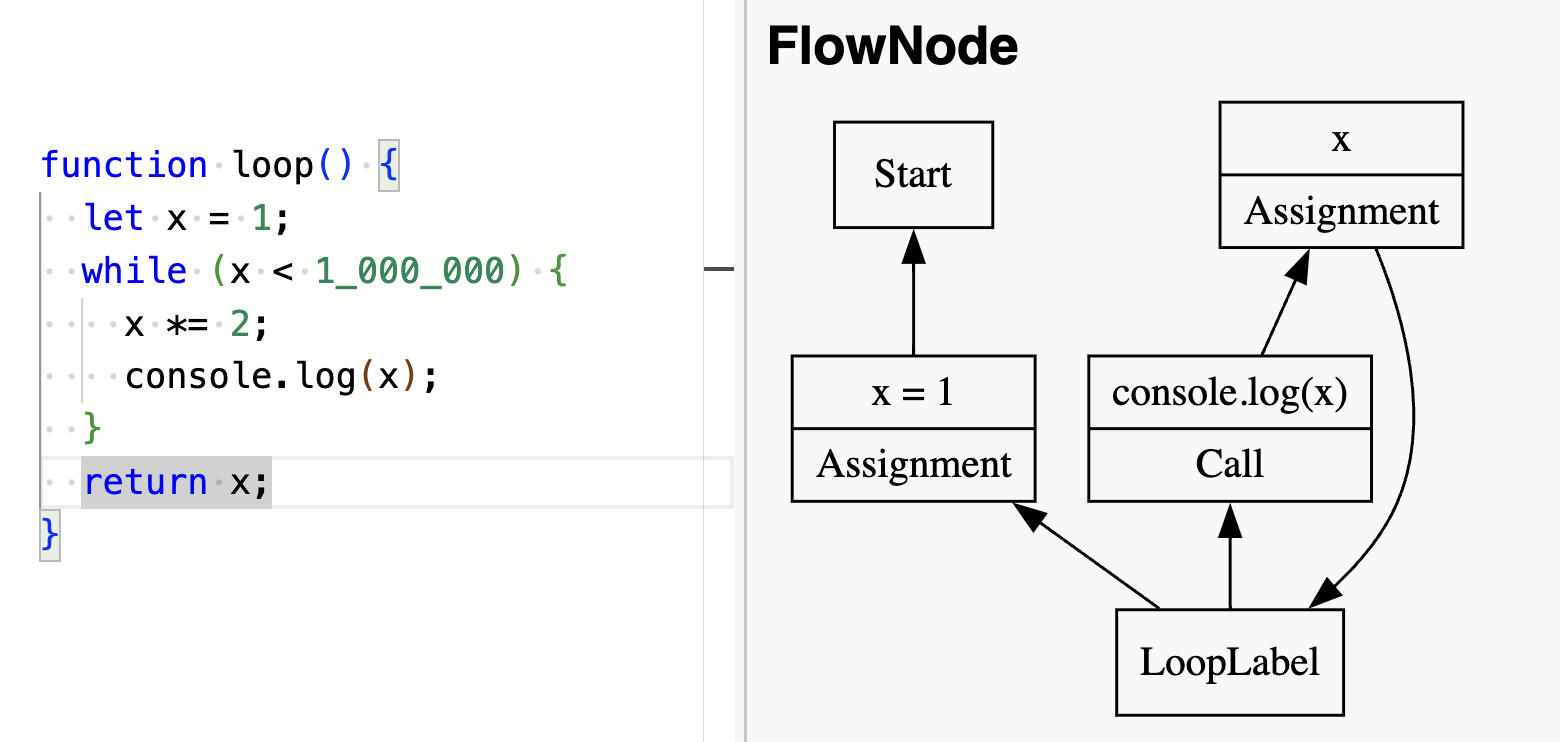 Control flow graph showing a cycle for looping code.
Control flow graph showing a cycle for looping code.
I eventually added this visualization to the TS AST Viewer. You can play around with it yourself to get a sense for how Flow Nodes work.
Turning Type Inference Upside-Down
With some intuition about Flow Nodes in place, the code I was seeing in the type checker started to make a lot more sense.
TypeScript greedily constructs the control flow graph in the binder (binder.ts), then lazily evaluates it as it needs to get types in the checker (checker.ts) or for display (tsserver.ts). This is backwards from how we think about narrowing in our heads: rather than narrowing types as you read down your code, TypeScript narrows types by traversing back up the control flow graph from the point where symbols are referenced.
Why does TypeScript do type inference this way? There are two reasons I can think of. The first is performance. In the context of the compiler, a symbol's type in a location is called its "flow type." Determining a symbol's flow type can be an expensive operation. It requires traversing the control flow graph all the way back to the root (usually the start of a function) and potentially computing some relationships between types along the way.
But often the flow type isn't needed. If you have an if statement like this:
|
Then the type of x inside the if statement is number. But that's not relevant to the type safety of this code in any way. There's no reason for TypeScript to determine the flow type of x. And indeed, it doesn't. At least not until you write x in the if block.
This leads us to a profound realization: until it becomes relevant, TypeScript has no idea what the type of x is!
If the type of x becomes relevant for type checking, then TypeScript will determine its flow type:
|
There may be many local variables in scope in your function. By only determining the flow types of the ones that are relevant for type checking, TypeScript potentially saves an enormous amount of work. This results in a more responsive editor and faster compile times. It also reduces TypeScript's memory usage: only the control flow graph needs to be stored permanently. Flow types can potentially be thrown away after they're checked.
The other reason that TypeScript does control flow analysis this way is to separate concerns in their code base. The control flow analysis graph is a standalone structure that's computed once in the binder. (This is the part of the compiler that determines which symbol x refers to in any location.) This graph can be constructed without any knowledge of what sort of analysis you'd like to do on it.
That analysis happens in the checker, checker.ts. One part of the compiler constructs the graph greedily, the other runs algorithms on it lazily.
This is what I was seeing in Anders's PR. He already had all the information he needed in the control flow graph. His PR just made the algorithm that ran over it a little more elaborate. Very few PRs need to change how the control flow is constructed. It's much more common to change the algorithms that run over it.
getFlowTypeOfReference
Speaking of algorithms, let's take a look at getFlowTypeOfReference, the workhorse of type inference. This is the function that determines the type of a symbol at a location. It's a real beast, clocking in at over 1200 lines of code. I'd link to it in checker.ts, but GitHub won't even display files this large!
getFlowTypeOfReference is so large because it follows the usual TypeScript compiler style of defining helper functions as local functions inside a large, top-level function. It quickly calls getTypeAtFlowNode, which is where the flow node graph traversal happens.
This function consists of a while loop that looks at the current Flow Node and tries to match it against all the different patterns that can trigger a refinement. If it doesn't find one, it moves up to the node's antecedent:
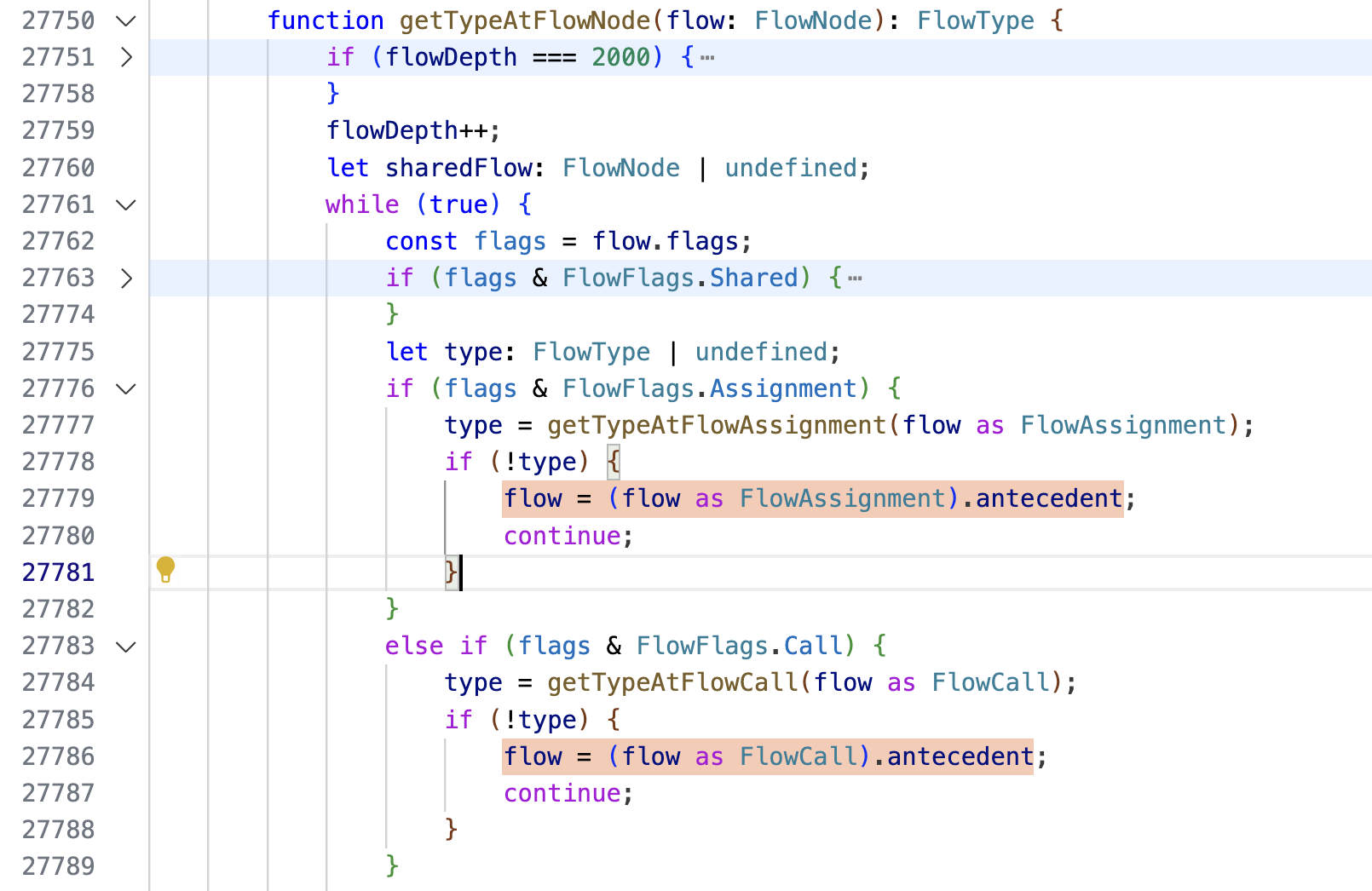 The code for traversing up the antecedent graph in getTypeAtFlowNode
The code for traversing up the antecedent graph in getTypeAtFlowNode
All the different patterns of refinement that TypeScript supports are represented by helper functions. Here's a sample:
- narrowTypeByTruthiness
- narrowTypeByBinaryExpression
- narrowTypeByTypeof
- narrowTypeByTypeName
- narrowTypeBySwitchOnDiscriminant
- narrowTypeByInstanceof
- narrowTypeByTypePredicate
- narrowTypeByEquality
- narrowTypeByOptionalChainContainment
It's interesting to think about what sort of code would trigger each of these. narrowTypeByEquality, for example, is a special case of narrowTypeByBinaryExpression. It would trigger on code like this:
|
(There's an assumeTrue flag that toggles behavior based on === vs. !==.)
narrowTypeByEquality is more subtle than you might expect! Take a look at this code:
|
If two values are equal to one another, then their type must be the intersection of their declared types. Very clever, TypeScript!
What about branching constructs? TypeScript traverses up through both branches and unions the result. This should give you a sense for why determining flow types can be expensive! (The code for this is in getTypeAtFlowBranchLabel.)
Conclusion
Hopefully this post has clarified what flow nodes are and how type narrowing is implemented in the TypeScript compiler. While this isn't important to understand for TypeScript users, I'm still amazed that, after having used TypeScript for eight years, it turned out to work completely backwards from how I thought!
