If you develop server code with TypeScript, you'll inevitably come up against the question of how to interact with your database. There's lots of type information in your database (the structure of the tables) and it's not immediately clear how to share that type information between the DB and TypeScript.
Over many years of working with TypeScript and Postgres, one of the most popular open source databases, I've developed some opinions and hard-earned knowledge. This post lays out the decision tree you face as you work with TypeScript and a database and presents my preferred techniques.
If you'd like to watch in video form, I gave a 30 minute talk on this at last year's TS Congress. Watching it again 16 months later, I have to say that it's pretty good! It goes into more detail on each option than this post does. You can follow along with the slides and sample repo if you like.
The DB Schema looks something like this:
|
Raw SQL + Hand-coded types
Say you write a query to fetch all the books in your database using node-postgres:
|
This code has a bug: it should be book.publication_year, not book.year. But because the the query returns an any type, TypeScript hasn't been able to flag it. No problem, we'll just write out an interface:
|
Voila! TypeScript flags the error and we can easily fix it by changing year to publication_year.
This is a big improvement over untyped code, and this tends to be the approach that developers fall into by default if they don't step back back and think about the problem of TypeScript and SQL.
But this approach also has a big problem: there's no single source of truth. If the database changes (say because of a migration) then our TypeScript types won't update. And nothing ensures that they types are accurate to begin with.
On the other hand, this approach has some strengths: it doesn't introduce any abstractions (you're just writing TypeScript and SQL) and it doesn't introduce any sort of build step into your project.
Pros and Cons of Raw SQL and Hand-Coded Types
- Pros
- Zero abstraction
- You do get some type safety
- Cons
- Repetition between DB + TS
- Types don't stay in sync:
- No Single Source of Truth
ORMs (TypeORM, Sequelize, Waterline, Prisma, …)
So you want a single source of truth. The first big question you have to ask is "where is the source of truth?" Since we're dealing with TypeScript and SQL, the two obvious choices are… TypeScript and SQL. If you want to make TypeScript your source of truth, then you'll be using an ORM, aka an Object-Relational Mapper.
Here's how we might define a Book table using TypeORM:
|
TypeORM handles the messy business of converting this class to SQL for us. And now we can use the Book class in our code:
|
And we have types! There's a single source of truth. Another nice property of ORMs is that they can often generate migrations for you, so that you don't have to write the SQL out by hand.
On the downside, ORMs are the classic example of a "leaky abstraction". The theory with an ORM is that you can treat the database as an implementation detail and you can just work in TypeScript. But in practice, that doesn't really work. To use an ORM effectively, you need to know SQL, you need to know TypeScript, and you need to know how to use the ORM. If you want to fine tune the performance of a query, say, you'll wind up working with your ORM to try to produce a really specific SQL query, which is just adding overhead over writing the SQL query directly. And if you work in an environment where there are multiple users of your database, perhaps working with other languages, then they'll feel like second class citizens since the database certainly won't be an implementation detail for them.
Using an ORM won't make you popular on Hacker News, but they are undeniably popular. You probably already know how you feel about them. Personally I'm not a fan, but they are ubiquitous and you'll eventually find yourself working on a project that uses one.
Pros and Cons of ORMs
- Pros
- Keep your types & DB in sync: single source of truth!
- Generate migrations for you
- Low boilerplate for simple queries
- ORMs are undeniably popular
- Cons
- The classic "leaky abstraction": You need to know SQL, TypeScript, and your ORM
- Performance is confusing
- They make other users of your DB second-class citizens
- Lots more churn in ORMs than in databases
Schema Generator (e.g. pg-to-ts)
So what if you're not going to use an ORM? Then your database will be the source of truth. But it's undeniably useful to have a TypeScript version of your database schema. So you can generate TypeScript from your live database. A tool that does this is called a Schema Generator, and they're an essential part of any system that uses the database as the source of truth.
The granddaddy in this space is SchemaTS, which got a lot of GitHub stars but was abandoned in 2018. So lots of people forked it. One popular one was PyST/SchemaTS, but that was abandoned in 2020. I needed to add some Postgres-specific features so I forked that one, updated it and re-released it as pg-to-ts. Give it a star! 😊
The idea with pg-to-ts (or any other Schema Generator) is that you point it to your live database and it outputs a dbschema.ts file:
|
Here's what the dbschema.ts file looks like:
|
For each table in your database you get two types: one for a complete row (i.e. the result of a SELECT statement) and one with just the properties you need to insert a new row (note the optional fields).
You can use this to adapt the "Raw SQL + Hand-coded types" example code:
|
This is exactly the same as the hand-coded version, except that we don't have to write the types by hand. Superficially this doesn't seem like a big change, but it's actually a huge win! In practice you'd generate dbschema.ts on your CI to make sure it stays in sync with the database.
This does add a build step. But schemas tend to change less frequently than code, so in practice most changes don't require this step.
Another issue is that we still had to manually add the Book annotation to our query to get the desired type out. For a more complex query, you may wind up writing duplicating logic with complicated Pick expressions or new interfaces based on your dbschema.
Schema Generators are a key building block for other tools (more on that below), so if you're not using an ORM then you should absolutely use a Schema Generator.
Pros and Cons of Schema Generators
- Pros
- Keep your types & DB in sync
- Key building block (more on this later!)
- Cons
- Add a build step
- Still have to manually add types to queries
- Some DB types are hard to model in TS (e.g. integers)
Query Builder (e.g. knex.js)
The next question to ask is whether you want to write raw SQL or use a query builder. Probably the most popular query builder for TypeScript is knex.js. Here's what it looks like:
|
A type! How does this work? Assuming you've run pg-to-ts to generate a schema, you can tell Knex about it using a type declaration:
|
This is the bridge between the Schema Generator and the Query Builder and it powers the type generation.
It's great that we get accurate types without having to write them out ourselves. You can generate much more complex queries using Knex.js and generally it will do a good job of inferring accurate types.
So what's the downside? Just as with ORMs, Query Builders are a classic example of a leaky abstraction. As your queries get more and more complicated, it becomes less clear that writing them with a query builder is any simpler than it would be to write them as raw SQL.
Pros and Cons of Query Builders
- Pros
- With schema generation, they get you accurate types for your queries.
- Less context-switching between languages.
- No added build step (beyond schema generation)
- Cons
- Another "leaky abstraction": You need to know TS, SQL, and your Query Builder
SQL → TS (e.g. PgTyped)
If you're not going to use a Query Builder, then you have another option: a tool reads your raw SQL queries, tests them against your live database and outputs types. This like a Schema Generator, but for your individual queries, not your database as a whole. The best example of this is PgTyped.
Here's what a query looks like with PgTyped:
|
What? any!? What's the point of that?
With PgTyped you have another step: you need to run the pgtyped command to get types for your query:
|
PgTyped read our tagged SQL query, inspected it against our live database (configured in config.json) and produced a types file:
|
PgTyped has produced two interfaces: one for query parameters (we have none, so this is void) and one for the results of our query. The third interface bundles these up for us. We can plug these back into our original code to get types:
|
Since it runs against your live database, PgTyped doesn't require a DB Schema. But with TypeScript's structural typing system, the IGetBooksResult interface is compatible with Book, so you can freely interchange them. You may wish to wrap your query to consistently use the DB Schema type.
PgTyped shines with more complex queries. You can use any features of PostgreSQL and PgTyped will follow along. There's no abstraction here, you're just writing SQL.
What are the downsides? As with other non-ORM tools, PgTyped does add a build step that you'll need to run as part of your development flow and on your CI (to make sure your types and queries stay in sync). Sometimes the types you get back aren't perfect, there are some issues around nullability. While the types are usually accurate, it can feel a little "duck typey" to have so many distinct but compatible types floating around. And finally, it's a lot of ceremony for simple queries like SELECT * FROM book.
Pros and Cons of PgTyped
- Pros
- You get types for your queries, however complex they are
- Zero abstraction: you're just writing SQL
- Cons
- Not all types can be accurately derived this way (nullability issues)
- Adds a build step
- A little "ducky" w/o dbschema
- Lots of fuss for simple queries
SQL→TS + a smidge of query building (zapatos, @databases, PgTyped + crudely-typed)
Finally, we get to my preferred approach! A Schema Generator produces the best-looking types and a Query Builder works with that schema. PgTyped excels at complex queries where you'd rather write raw SQL. So the idea here is to use a minimal, TypeScript-first query builder that won't tempt you into writing complex queries with it because it doesn't support them. You should be using PgTyped for those, anyway.
Enter: crudely-typed!
crudely-typed (which I built at my last job) is a query builder that generates only relatively simple queries with a focus on working with your dbschema to get perfect types. Here's what it looks like:
|
You still have to regenerate dbschema.ts when your DB Schema changes, but there's no build step or overhead for the simple queries that crudely-typed supports. These include the basic CRUD (Create, Read, Update, Delete) queries as well as some very minimal support for 1-1 joins. Because it knows about your DB Schema, you'll get nice-looking type signatures on your functions:
|
In practice this covers 90+% of the SQL queries that you run in most applications. For the remaining 10% you can fall back to using PgTyped. The net effect is that you have a single source of truth (your database) and you get accurate TypeScript types with relatively minimal fuss.
While I've never personally used them, I believe zapatos and @databases follow a similar approach.
Pros and Cons of hybrid Schema Generator + Query Builder / PgTyped
- Pros
- Zero abstraction/overhead for complex SQL queries (PgTyped)
- Minimum fuss, dbschema types for simple queries (crudely-typed)
- Cons
- Adds a build step
- You might be tempted to put logic in JS instead of SQL, i.e. run 10 crudely-typed queries instead of one SQL query.
Conclusion
Here's the final decision tree from my slides:
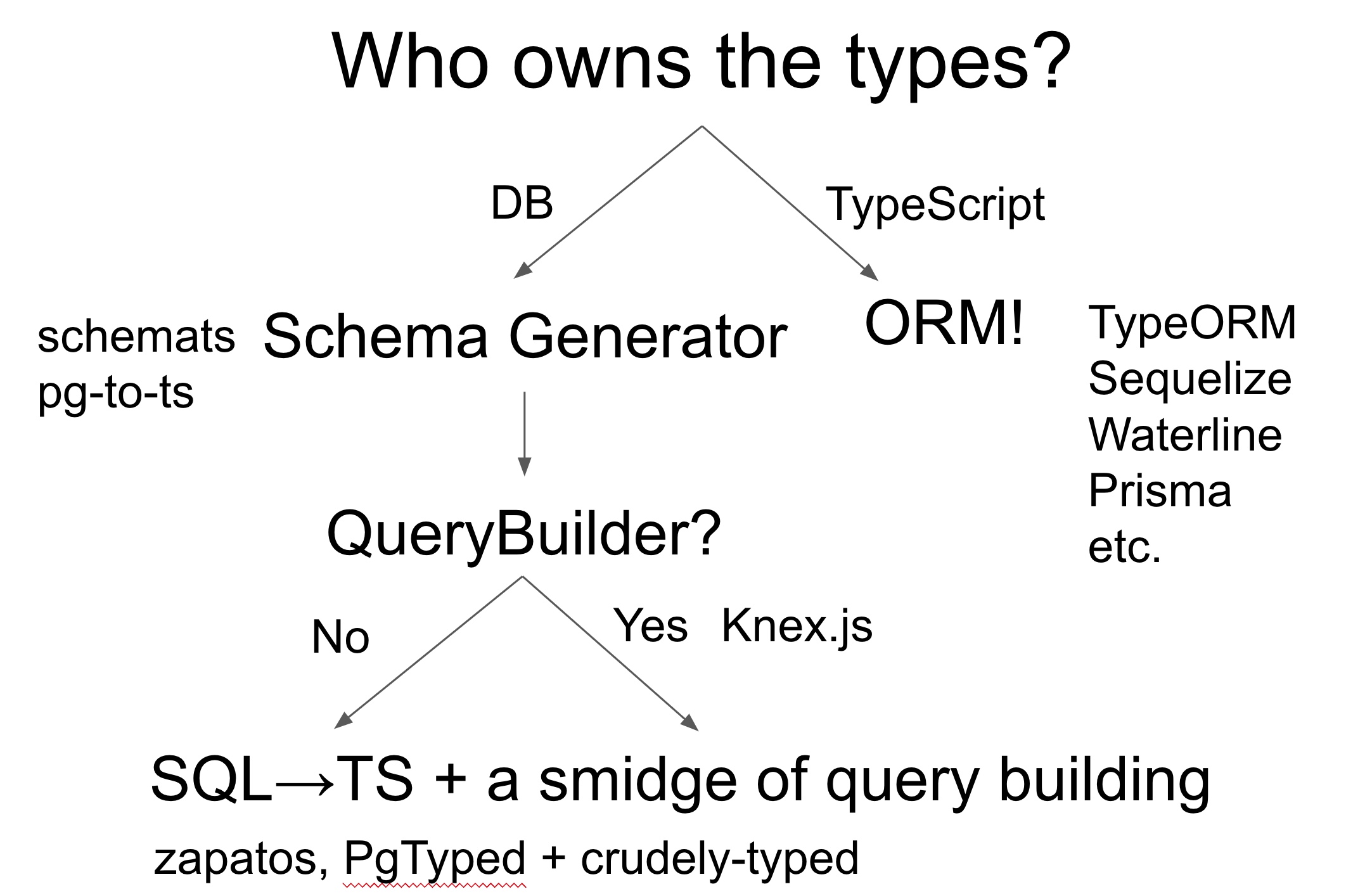
There are no perfect choices here. Depending on how you feel about ORMs and Query Builders, you'll wind up in a different place. Regardless, the key thing is to make a conscious, informed decision about how you want to combine TypeScript and SQL. However you do it, try to have a single source of truth.
The final, hybrid option is where I've wound up after years of dealing with this problem. How do you like to work with databases in TypeScript? Let me know in the comments!
